The Service Cutter suggests a structured way to service decomposition. This tutorial helps you to work with the Service Cutter. You should have access to a test installation or install the Service Cutter on your machine in order to try the samples.
You will learn how to import data into the Service Cutter and analyze service cuts. The last section outlines two possible usage scenarios.
Core Concepts
- Nanoentities (see definition) are the building blocks of services.
- A User Representation is a concept familiar to the architect that can be used to feed the criteria information into the Service Cutter.
- A Coupling Criterion describes an architecturally significant requirement why two nanoentities should or should not be owned by the same service. These criteria define the semantic model on which the Service Cutter is built on.
Data Import
The importer tab allows you to import nanoentities and user representations.

Currently updates are not possible. You have to import a new model after applying changes to the files.
Domain Model
To begin with, a domain model in the form of an ERM needs to be imported.
A simple domain model can be found in the samples folder. Let's try with ServiceCutter/Samples/ddd_1_model.json for now.
User Representations
To suggest good service cuts, we need more data. The file ServiceCutter/Samples/ddd_2_user_representations.json enhances the domain model with Use Cases, characteristics of the nanoentities and responsible roles.

Now we have all the data we need. Let's continue with the analysis.
Service Cut Analysis

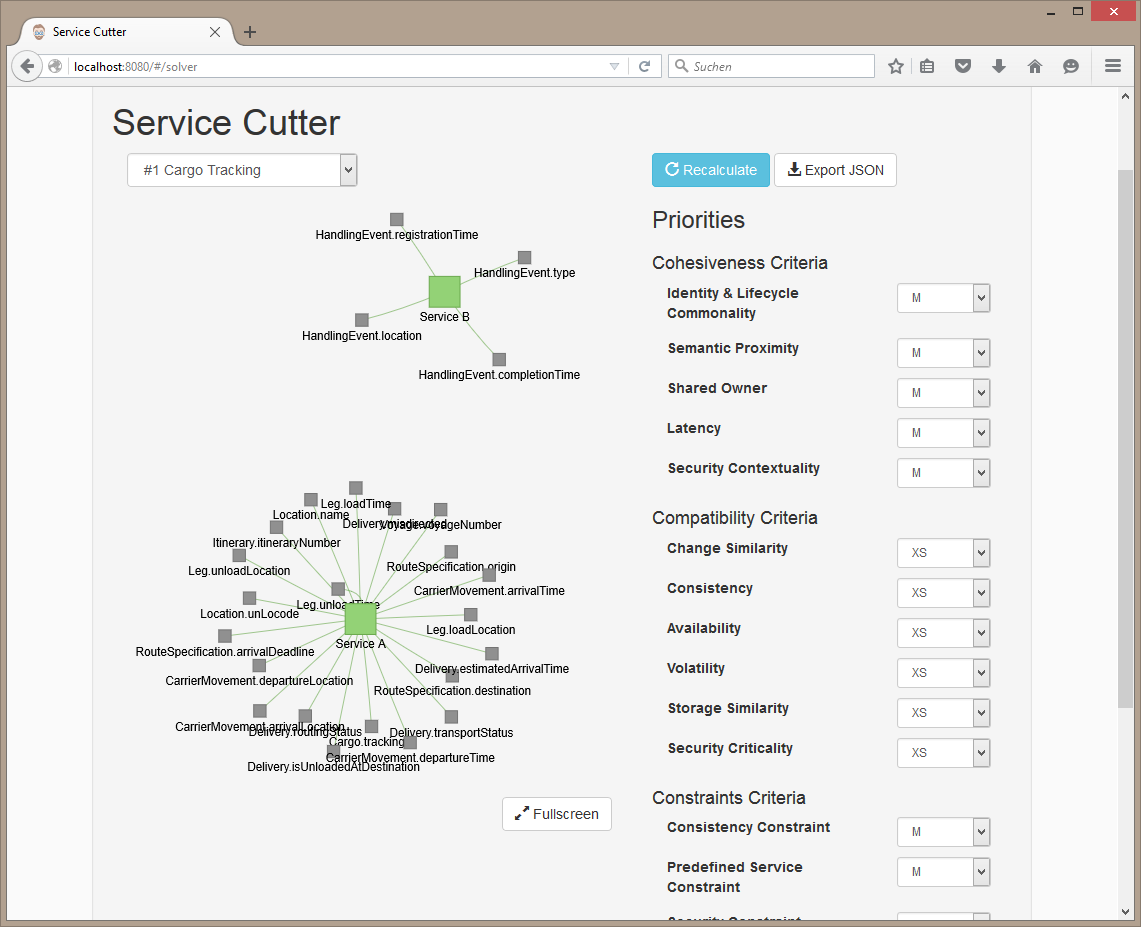
The solver tab allows you to see candidate service cuts, choose an underlying algorithm, and define criteria prioritities.
Algorithms
The Service Cutter maps all imported data onto a graph. The nanoentities are the nodes and the coupling between nanoentities is stored on weighted, undirected edges.
The Service Cutter uses graph clustering algorithms to find densely connected clusters which are presented as candidate services. Currently two different algorithms are supported: The "Epidemic Label Propagation" by Leung et al is non-deterministic and finds an optimal number of clusters. Use the recalculate button to see different service cuts.
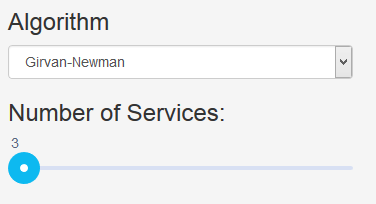
The Girvan-Newman algorithm by M. Girvan and M. E. J. Newman is deterministic and finds a given number of clusters.
Hint: You cannot see different service cuts with Girvan-Newman as this algorithm is deterministic. You have to adjust the parameters to see different service cuts.
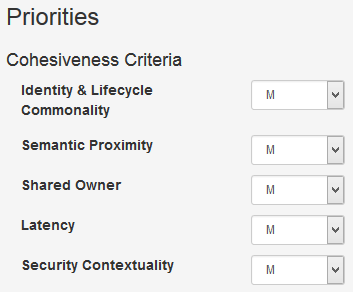
Parameters
The parameters can be used to influence the candidate service cuts. Modify the coupling criteria in such a way that they reflect the your system's context. Consistency for example is significantly divergent in a banking environment compared to an online social network.
Analysis mode
Activate the analysis mode to understand the implications of a candidate service cut.

The analysis mode activates the following features:
- An connection between the services is drawn when a use case exists that uses nanoentities of both services.
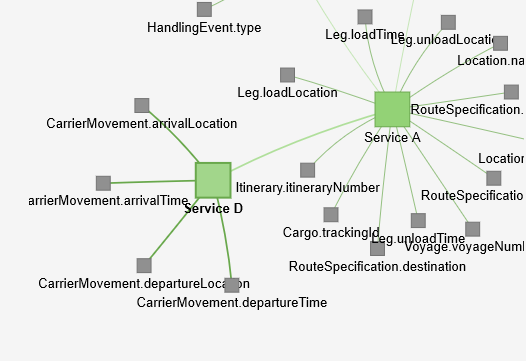
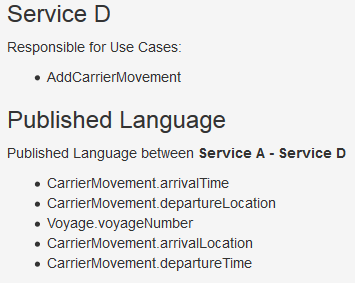
- You can click on a service or a connection between two services and the Service Cutter will display the Published Language of the selected service.
Hint: The analysis mode is only available with use cases present.
Scenarios
We would like to highlight two possible usage scenarios of the Service Cutter.
Green field
The pleasant scenario is the “green field”. You have not written a single line of code but already gathered an extensive set of Use Cases, an ERM and other characterizations. You load all this data into the Service Cutter and use the suggested service cuts for an inspiring discussion with your team’s architects. Finally, you agree on a set of services and proceed to building them.
-
"Microservices" by Martin Fowler
Monolith to microservice
The likely scenario with existing software is the transition from a monolith to a microservice architecture. You’ve been working on an application for quite a while and you and your team only implemented a single service. After carefully reviewing your architecture, you decided that the time has come to split your application into services. This leaves to you with one big question: "Where shall I start?" The Service Cutter is able to identify candidate service cuts with a given number of services. You can use the Girvan-Newman algorithm and set the number of clusters to two. Then iteratively increase the number of services by one and you will see a possible path towards an architecture based on services.
-
"MonolithFirst" by Martin Fowler
Service Cutter Benefits
- By requesting different user representations, an architect is challenged to analyze which user representations and characteristics are relevant in his system. He might use the user representations as a check list for requirements engineering.
- The user representations and coupling criteria can be used to educate junior architects or students on the driving forces of service decomposition.
- The Service Cutter provides candidate service cuts based on the defined user representations. With these candidate service cuts the architects expectations of the number of services and their definition is either verified or challenged.
- The greenfield scenario as well as an iterative approach from moving from a monolith to service orientation are supported by the Service Cutter.
- Use cases are assigned to their responsible service. The published language between services is displayed in order to assist the development of services and their interfaces to each other.
- By storing the candidate service cuts, architectural decisions can be persisted and documented (not yet implemented).
Further Resources
- Wiki with more details
- Service Cutter source code
- ESOCC 2016 article on Service Cutter (authors copy)
- Bachelor thesis by Lukas Kölbener and Michael Gysel (PDF)